* 使用Kindling观测服务拓扑与性能
📌 安装Kindling后,以下功能会自动启用。
感谢大家对Kindling感兴趣,为了让大家可以快速上手使用Kindling,我们提供了在线Demo方便大家去探索Kindling功能。
Demo场景介绍
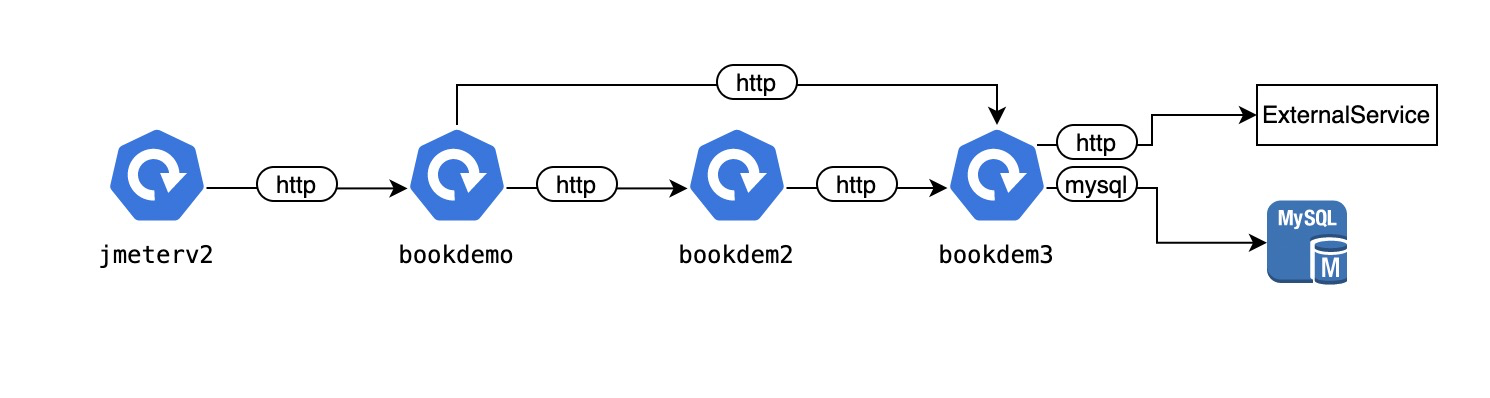
在线上Demo中展示的是我们内部一套k8s环境的可观测数据。在这一套k8s环境中我们部署了3个微服务分别是:bookdemo, bookdemo2,bookdemo3,同时为了保持一定的访问流量,我们部署了一个jmeter的deployment,以一定时间间隔发送请求到bookdemo微服务。我们的微服务访问都以k8s servicename方式访问。
微服务的真实拓扑如下:
目前Kindling发版功能
目前Kindling已经发布了轻量版,轻量版的Kindling 探针相当于一个prometheus exporter,这样方便大家可以将Kindling的能力很容易地集成到自己的prometheus监控体系。同时为了这些指标能给大家一个直观的价值感受,Kindling默认提供了1个grafana插件展示了大家日常监控过程的大部分场景。这个grafana插件主要提供了4个grafana dashbord,分别如下:
- Topology
Topology dashboard主要功能是将Kindling 探针自动发现的应用网络调用关系以拓扑形式展示,同时提供了灵活的应用层指标以及网络层指标选择能力,方便大家可以直接在拓扑上定界集群内workload调用异常问题、workload调用性能问题、DNS问题、网络质量问题、workload以及pod负载不均衡等问题。 - Workload Detail
Workload Detail dashboard主要展示的是workload黄金指标(错误、延迟、访问量)信息,这些指标可以帮助大家快速了解集群中workload的健康情况。除了提供整体的指标查看之外,这个dashboard会将一些错误请求信息展示出来,方便大家了解错误接口。更值得大家关注的还有一个功能,这个dashboard会进一步把应用慢请求的执行过程进行分阶段具象化(参考chrome network timing analyze),方面大家去判断请求的延时抖动到底是因为应用本身还是网络问题,实现快速的应用问题和网络问题定界。 - Network Detail
Network Detail dashboard提供了单纯的网络分析视角,主要展示的是网络性能指标,在这里大家可以了解到集群以及workload整体的网络性能、流量情况,同时大家也可以追踪具体workload之间的网络访问指标以及流量访问大小,甚至可以追踪到pod粒度的丢包连接。 - DNS Request Detail
DNS Request Detail主要提供的功能是分析workload的DNS访问可用性以及访问性能,可以提供单纯的DNS分析视角分析dns解析异常、解析慢是否对workload的访问造成影响。
以上dashboard都是Kindling默认支持的,如果大家有其他展示的一些诉求,大家可以参考我们的指标详情 自定义自己的展示场景。同时我们也欢迎大家给我们在issue里面提供这些需要自定义的场景,方便我们更好的迭代。
核心功能使用介绍
使用Topology dashboard
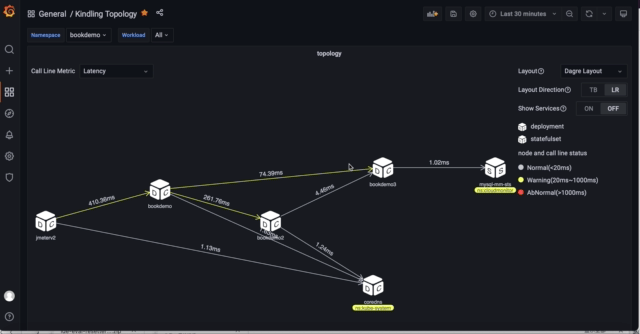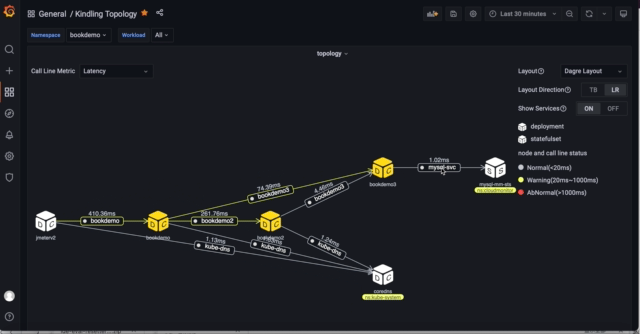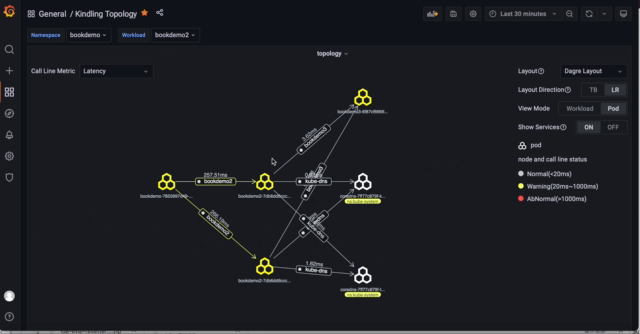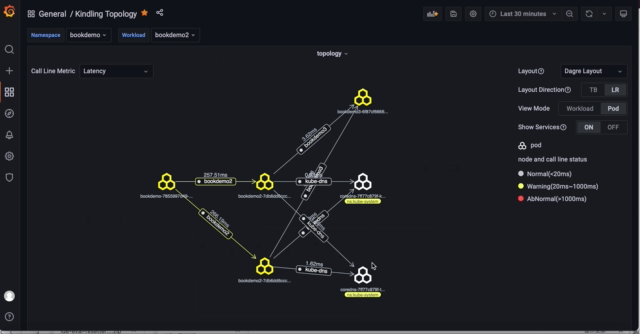
1)选择namespace, 路由到具体namespace拓扑
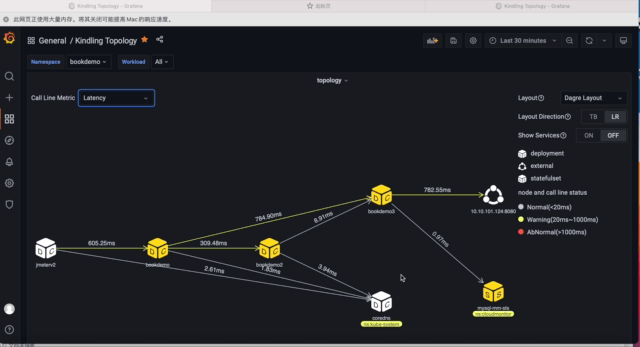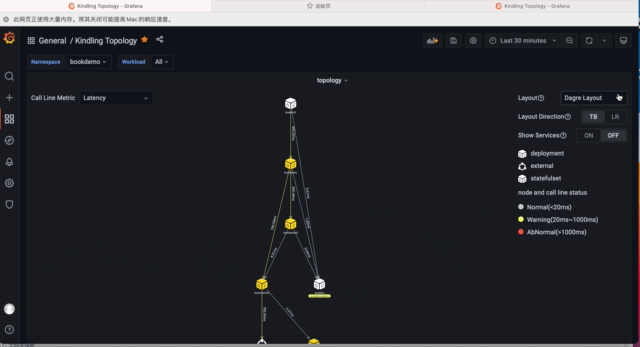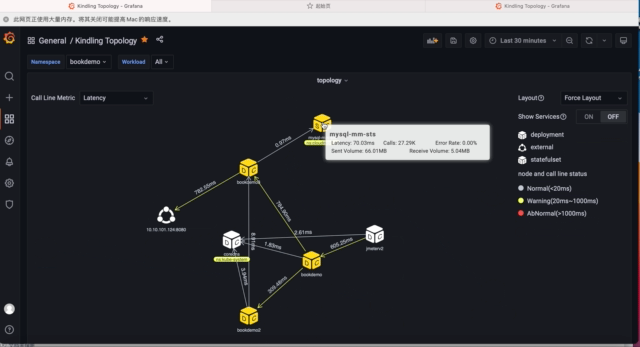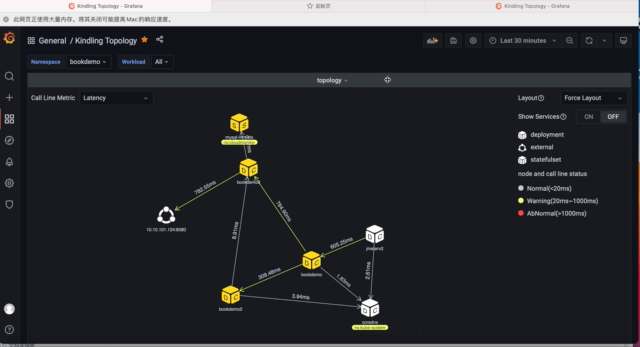
为了让拓扑尽量展示简单,默认拓扑图展示是namespace, external-ip,dns节点之间关系拓扑图,可以根据namespace下拉框选择具体namespace下的workload之间的拓扑图,demo可以选择bookdemo namespace。选择了namespace之后会展示出当前namespace所有workload之间、和其他namespace workload的交互以及当前namespace对外部IP的交互。
值得注意的是,因为grafana variables的查询限制,目前还不对variables设置复杂查询,所以下拉框的workload展示的是有接收到流量的workload. 对发起请求的workload并不会展示。(大家后续也可以在自己环境中可以使用kube-state-metrics的指标替换)
2)默认展示的拓扑指标是平均延时,大家可以在自由选择拓扑图展示的指标:
- Latency:一段时间的平均 延时
- Calls: 一段时间的吞吐量/访问量
- Error Rate:错误率
- Send Volume: 发送的网络流量大小
- Receive Volume: 接收的网络流量大小
- SRTT:平滑RTT,用来衡量网络延时

3)拓扑图进一步过滤和展示
拓扑图具有一些过滤展示能力,通常可以帮助大家实现以下场景:
- 展示workload拓扑之间service依赖关系
- 过滤某个workload下pod之间的网络流量
- 展示pod调用之间service的依赖关系
4)自定义红色、黄色的阈值设置

5)拓扑布局调整
使用Workload Detail dashboard
1)根据头部筛选条件,选择具体workload
选择具体namespace下的具体workload信息。因为workload的黄金指标都来自于协议的协议,可以在Protocol下拉框中选择具体协议,查看具体协议的请求情况。

目前Kindling协议支持情况如下:
| 协议 | 识别方式 | metric解析支持 |
|---|---|---|
| HTTP | 根据端口识别(无默认配置),自动识别 | 支持 |
| DNS | 根据端口识别(默认配置53),自动识别 | 支持 |
| Kafka | 根据端口识别(默认配置9092),自动识别 | 支持 |
| Redis | 根据端口识别(默认配置6379),自动识别 | 支持 |
| MySQL | 根据端口识别(默认配置3306) | 支持 |
2)服务端性能分析以及下游依赖影响分析
对于一次请求探针会分别在服务端和客户端分别采集数据,在服务端采集的数据不包含网络传输时间,在Request Detail 的panel进行查看。
当大家发现一个workload性能有问题时,有可能下游依赖的影响,dashboard提供对下游依赖的统计和请求分析,大家可以在Upstream Performance的panel里面进行详细查看。

3)tracing具体慢请求,定界网络问题
我们对一个请求整体延迟分成来以下三个阶段,并且对延迟标识一定状态,方便大家快速定界到请求性能的问题。一般来说,Process阶段异常代表应用本身时间长,RespXfe阶段异常代表网络性能问题或者传输的内容过大。如果是网络性能问题可以去network detail dashbord根据src_ip和dst_ip找到具体的网络链接查看是否出现过网络性能问题。
| ReqXfe :代表请求发送完的时间 | normal: latency <= 200ms |
|---|---|
| warning: 200<latency<1000 | |
| abnormal: latency >= 1000 | |
| Processing:时间代表收到应用返回第一个字节的时间,用来衡量应用本身的处理延迟 | normal: latency <= 200ms |
| warning: 200<latency<1000 | |
| abnormal: latency >= 1000 | |
| RspXfe :代表响应传输时间 | normal: latency <= 200ms |
| warning: 200<latency<1000 | |
| abnormal: latency >= 1000 |

4)如何配置三个阶段不同颜色的阈值?
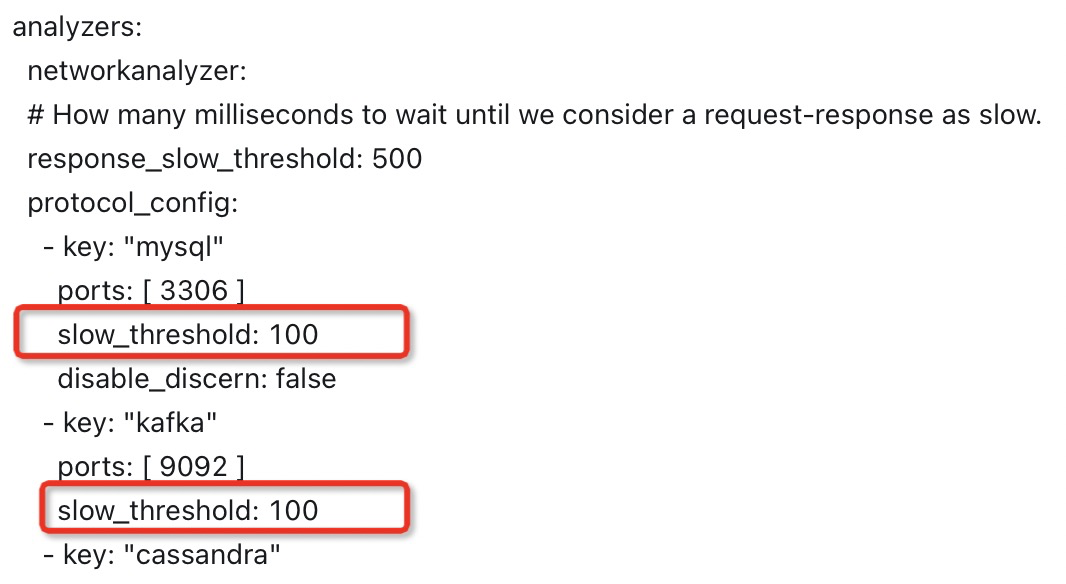
目前每个阶段状态判断阈值还未可配置,后续Kindling将开放给大家自由配置。但是出于性能和成本考虑,我们并不会把每一次请求的执行记录下来,我们只把慢的和有错误率的记录下来。关于请求整体的慢阈值设置可以修改kindling configmap,针对不同的协议我们都有具体的慢阈值设置,目前我们会把大于100MS的请求详细执行生成相应指标。
另外关于P50,P95等指标,后续会不断完善,如果大家对这一类指标比较紧急,请提交feature request 给我们。
其他功能探索
其他功能比如:network detail, DNS detail,因为这些功能的展示方式相对单一,大家可以在在线地址中自行体验。